Data & Mores compliance løsning er bygget til præcist at kunne identificere og klassificere data, og dernæst at vise dette overskueligt til en organisations medarbejdere, således at de er i stand til at beslutte, om det identificerede data skal slettes eller opbevares. Denne proces sker på tværs af datakilder. Data & Mores compliance løsning er ikke blot bygget på viden om dansk sprog og danske forhold, men også på viden om en del andre sprog. Løsningen indeholder således en komplet klassificeringsmotor.
Data & More har et team, der hver dag arbejder på at opdatere leksikon og optimere klassifikationer på flere forskellige sprog, hvilket sker på baggrund af tilbagemeldinger fra mere end 50.000 slutbrugere. Data & More anvender en meget avanceret søgestruktur, der er bygget op omkring regler, modregler, skræddersyet AI, skræddersyede boolean søgelogikker, OCR og billede AI. Alt dette giver en meget præcis fremsøgning af personligt identificerbare data.
Data & More har bygget digitale leksikon og biblioteker, der indeholder mere end 500.000 objekter på 25 forskellige sprog, hvilket bruges til klassifikationer på forskellige sprog. Alt dette sparer den enkelte kunde for en masse vedligeholdelsesarbejde. Vi har aldrig oplevet en kunde være i stand til at bygge klassifikationer op på egen hånd med succes, selvom flere har gjort forsøget.
Data & More klassificerer de forskellige typer af personligt identificerbare data som forskellige dokumentklasser. Nedenfor vises en oversigt over de vigtigste dokumentklasser. Hver af dem er bygget op efter en masse forskellige under-dokumentklasser med mere specifikke klassifikationer. Eksempelvis indeholder Data & Mores dokumentklasse for National ID mere end 25 forskellige måder at søge et dansk CPR nummer frem på, da det muliggør en så præcis fremsøgning af danske CPR numre som muligt. Et andet eksempel er tyske pas, som Data & More har mere end 5 forskellige måde at søge frem osv.
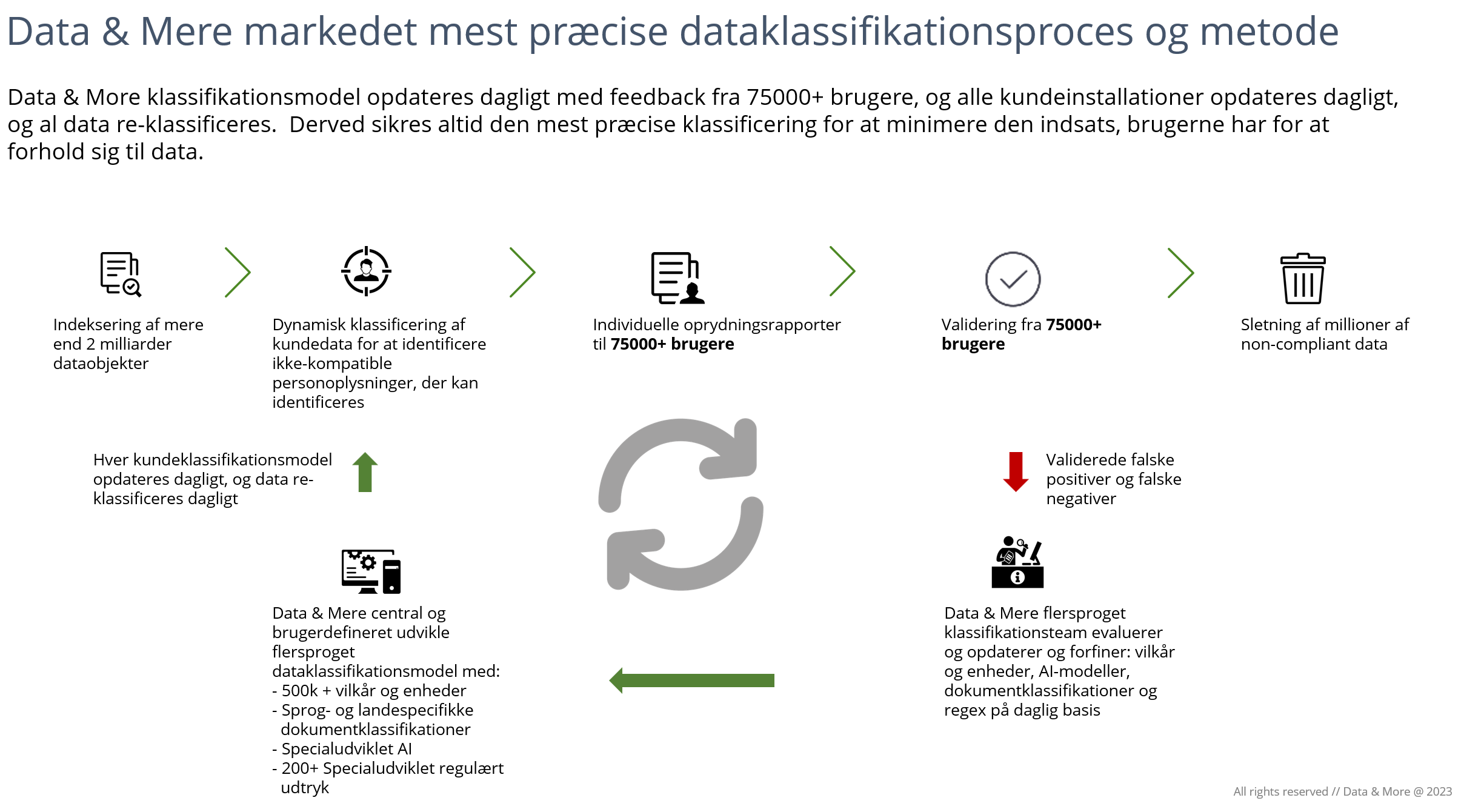
Data & More har en unik og dynamisk klassifikationsmodel, der opdateres dagligt på baggrund af brugerfeedback om falsk negative og falsk positive resultater. Vores centrale dataklassifikationsmodel opdateres dagligt, og alle kundernes løsninger opdateres ligeledes hver nat, og alle data omklassificeres med de nye forbedringer, for at sikre, at slutbrugeren får den bedst mulige og mest korrekte klassifikation. For de fleste andre klassifikationsmotorer er dette en proces, der kan tage op til flere måneder.
Oversigt over Data & More feed back loop:
Her er et overblik over alle de vigtigste dokumentklasser sammen med de relevante GDPR artikler:

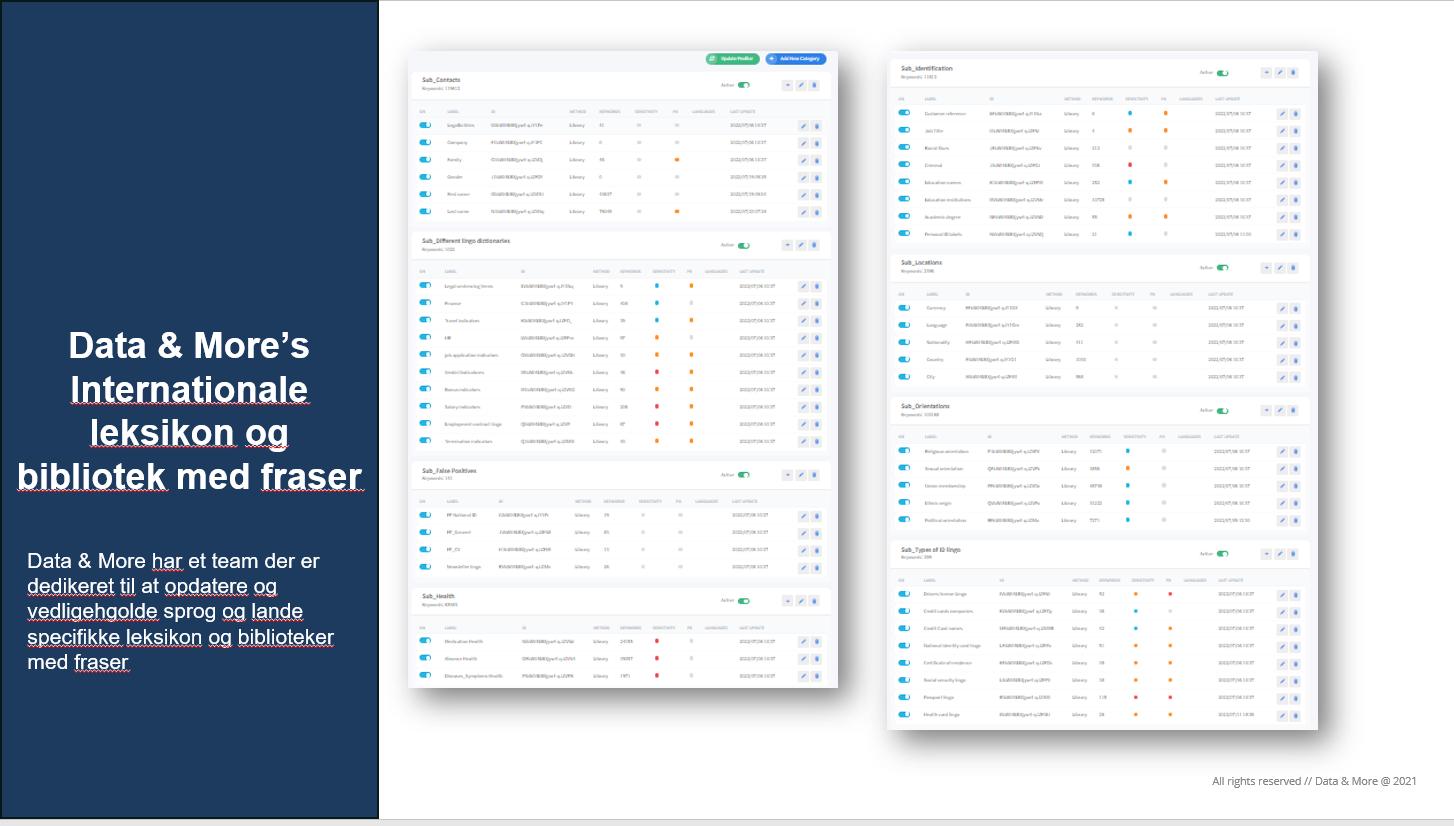
Skærmbillede af nogle af Data & Mores mere end 500.000 leksikon af enheder, navne og specifikke fraser, som vedligeholdes af vores klassifikations team:
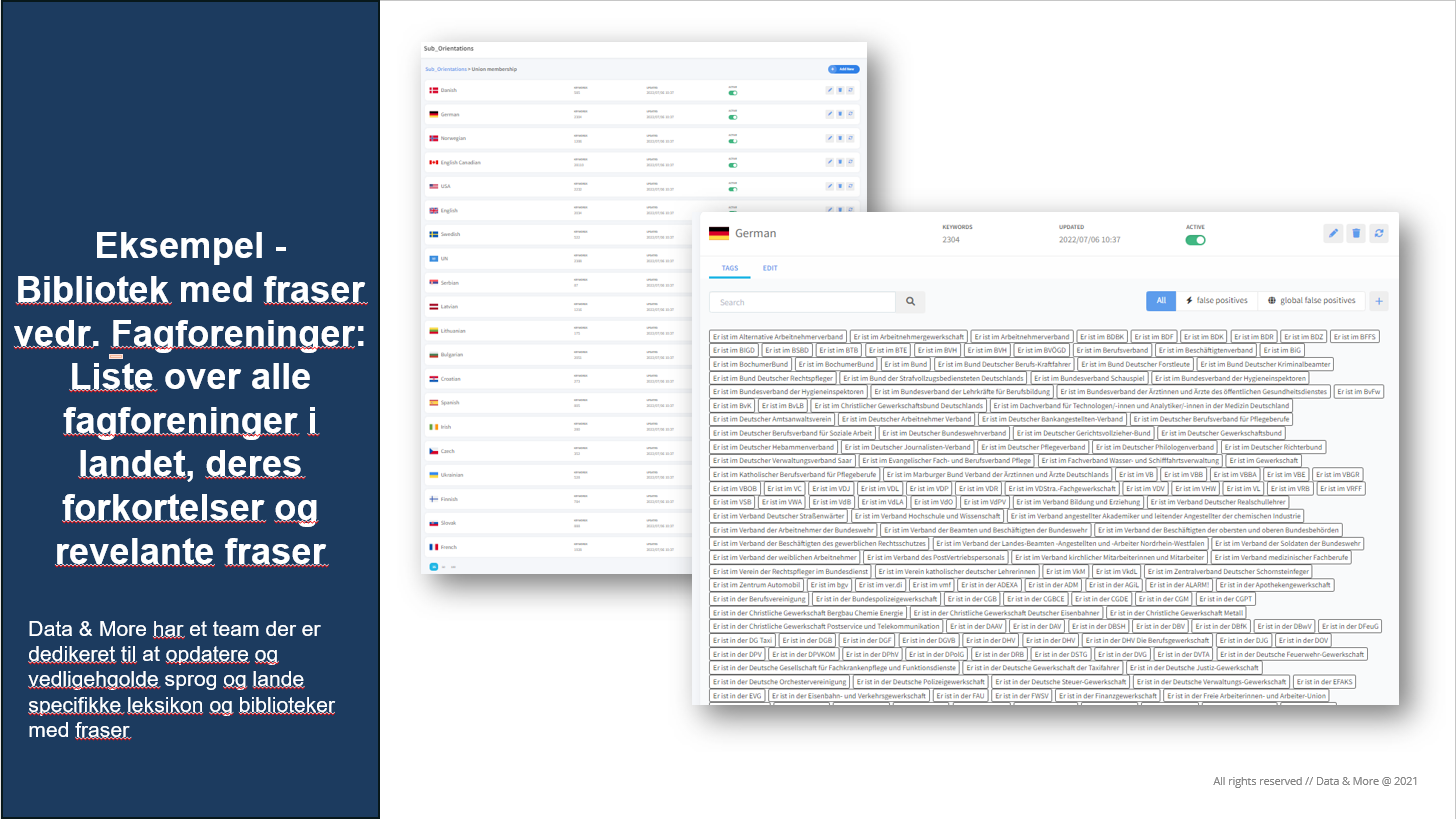
Eksempel: Bibliotek for fraser omhandlende fagforeninger. Liste over alle fagforeninger i et land, deres forkortelser og relevante fraser: