Overview of the different types of personal identifiable data that the Data & More classification automatically identifies
The Data & More solution is built from the ground up to be able to most precisely identify and classify data, then to be able to effectively show this to employees so that they can decide whether data can be deleted or stored. Next, delete data across sources. Data & More solutions are built on deep understanding of language and the local difference in languages and local country specific entities and regulation. One of the key benefits of the Data & More solution is that the model build and constantly improves and dynamically added new classifications based on user input and regulation input.
Data & More has an entire classification team that updates dictionaries and classifications in several languages and optimizes the classification with answers from over 75,000 employees. Data & More uses very advanced custom build: advanced rules with multiple counter rules, custom developed AI, custom Boolean queries, custom exclusions, OCR, custom picture AI to be able to precisely identify personal identifiable data.
Data & More has built dictionaries and phrase libraries of over 500,000 objects in 25 languages and added document classifications in several languages. All of this would have to be made and maintained by the customer. We have never seen it succeed. Several tried unsuccessfully.
Data & More classifies the different types of personal identifiable data into document classes. Here is an overview of the high level document classes. Each of these document classes are build up of a lot of different sub document classes with more specific classifications, e.g. the Data & More document classification for National ID consists of individual classifications for the different national ID's that exist. As an example, Data & More has more than 25+ different methods to be able to precisely identify a Danish CPR (The Danish National ID no.), for the German Passport we have 5+ different methods etc.
Data & More has a unique and dynamic classification model that is updated daily based on user feedback on false negative and false positives. Our central data classification model is updated daily and all customers solutions are likewise nightly updated, and all data reclassified with the new improvements to ensure that end-user have the best possible and most accurate classification. For most other classification engines, this is a process that can take up to several months.
Overview of the Data & More dynamic feed back loop:
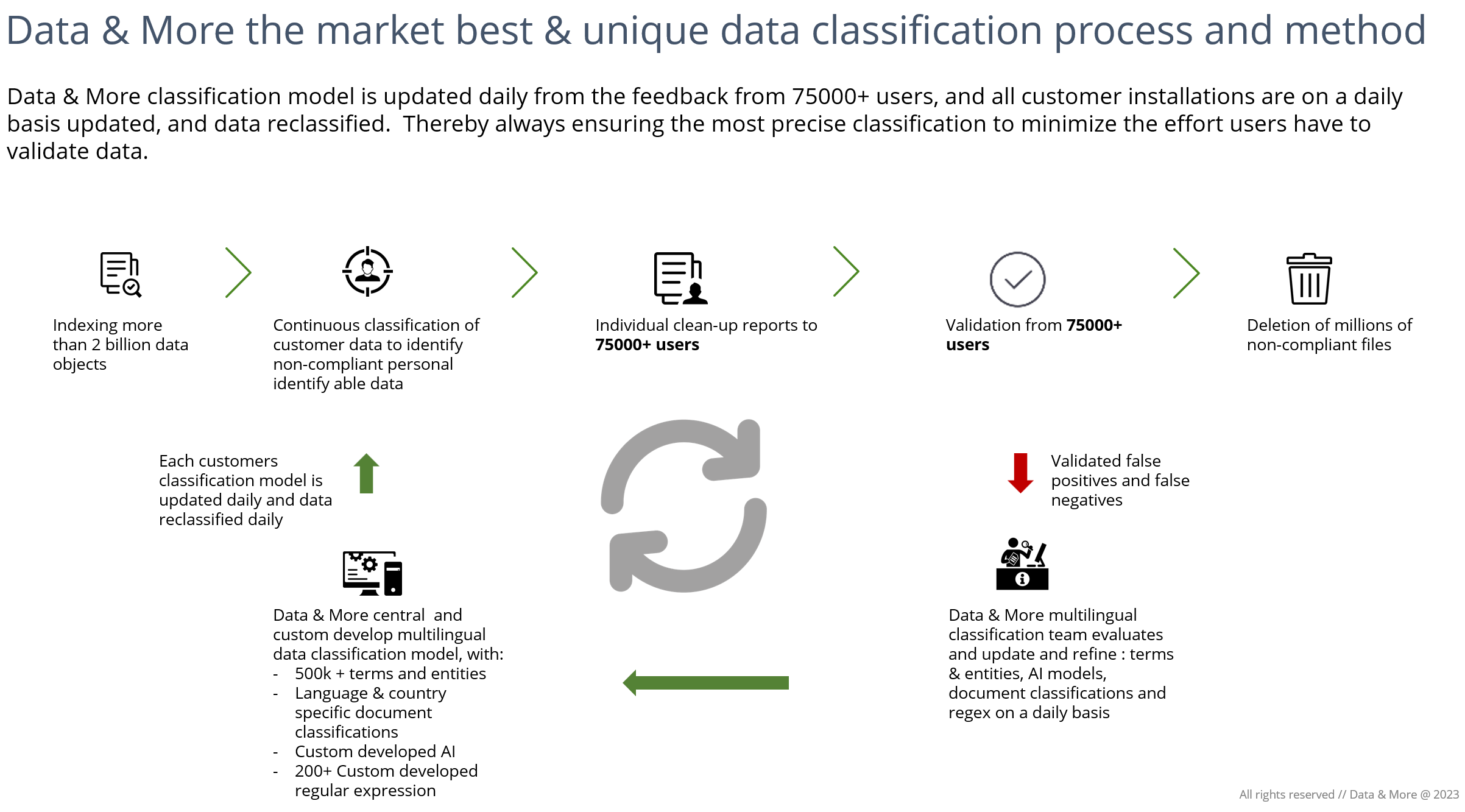
Here is an overview of all the different high level document types:

Here is an overview of all the different high level document types with the relevant GDPR articles

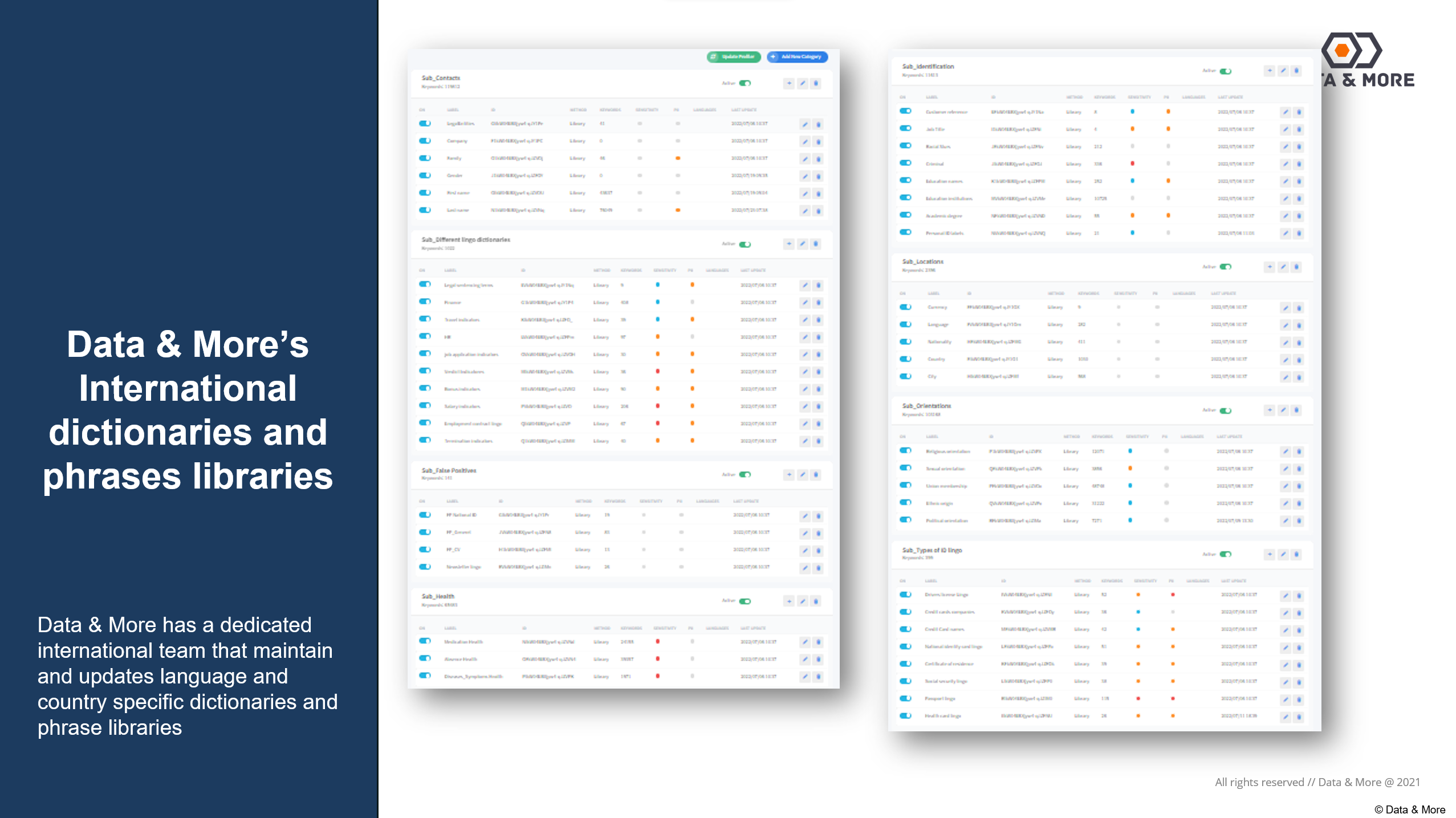
Screenshot of some Data & More more than 500.000 entities, names and specific phrases that is maintained by our classification team:
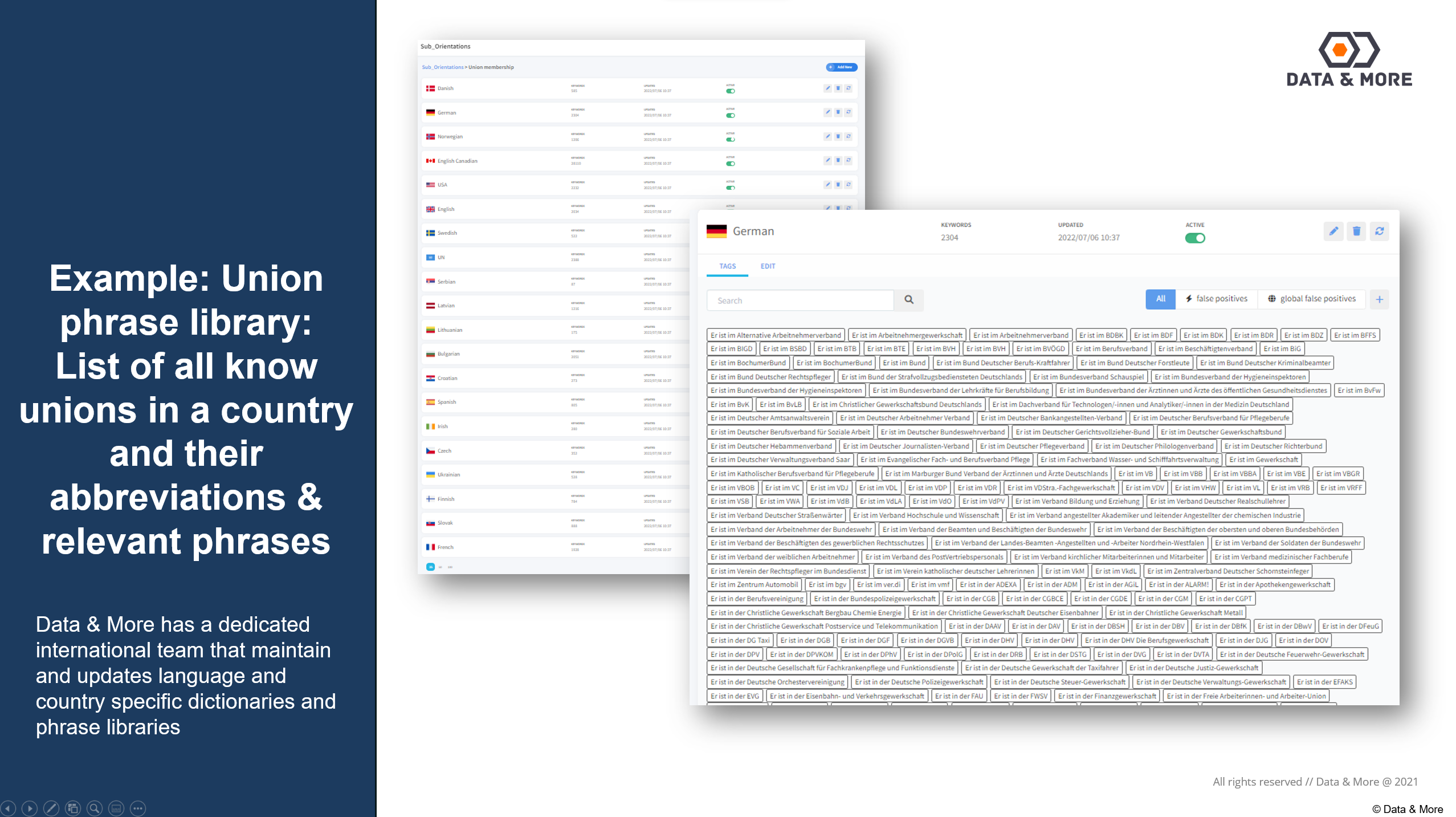
Example: Union phrase library:List of all know unions in a country and their abbreviations & relevant phrases
Additional Classification articles: